
探智立方发布DarwinML 2.0升级:一站式全自动引领AutoML企业赋能
AutoML是当今人工智能界最受瞩目的核心技术之一,被视为改变人工智能发展的核子武器。这项技术的核心价值在于将复杂繁琐的模型设计过程简化并自动化,智能地体现数据的价值,提高企业的生产力和竞争力。目前市场中大多数AutoML平台产品仍以面向数据科学家等专业建模人员为主,将模型训练中的各种环节自动化,以提升建模效率,而在企业中的部署和应用过程中仍需较高的人工智能的技术能力及人力,对数据科学家与专业AI团队的依赖度较高,导致AutoML技术在企业中的实际使用门槛依然较高。
昨日,探智立方发布了一站式全自动机器学习平台DarwinML 2.0升级,在为企业带来全流程自动化的建模能力的同时,显著提升了AutoML技术在企业中应用和部署的易用性,让普通业务人员也可以参与AI开发,帮助更多企业实现人工智能带来的的商业价值,引领企业AI赋能。
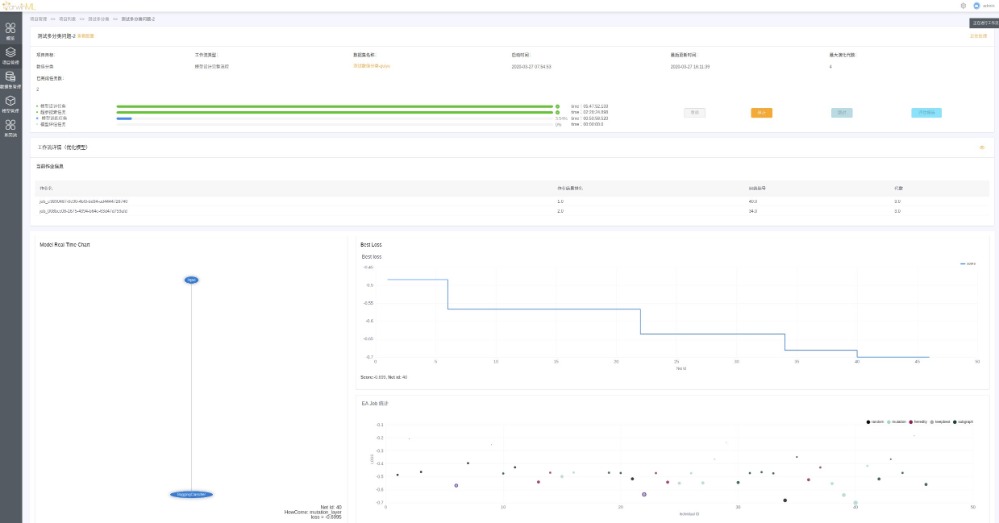
在业内备受关注的DarwinML平台是探智立方自主研发的以演化算法技术为基础的AI赋能平台,它能够针对客户导入的数据,自动生成符合业务场景的最优化人工智能模型,并根据业务实时反馈自我演化和迭代,做出更为精准的模型设计,在大幅节约数据科学家建模时间的同时,让缺乏人工智能专业人才的企业也能设计出满足业务场景的人工智能模型,真正实现了企业应用AutoML技术的全流程自动化和定制化。
升级后的DarwinML 2.0版本,为企业AI技术的落地提供了的更加高效的解决方案——把数据预处理、模型全自动化设计,模型优化全部自动化。DarwinML 2.0中提供了更加丰富的自动特征提取,分析及生成功能、以及自动数据扩增功能,帮助企业AI建模人员和业务人员在企业的数据湖中抽取有效的数据,并把不同系统的数据自动化整理为可以直接入模的数据,降低了使用人员对数据准备和数据分析的复杂难度。同时,DarwinML 2.0优化了流式推理引擎,自动发布设计模型到生成系统,并根据生产系统的反馈,优化模型,优化数据标签;在提供高吞吐低延迟的基础上,还能够零活的对接企业的应用,方便提供“推”,“拉”不同方式的接口与企业对接,实现一键发布,一键上线。
同时,探智立方还公布了DarwinML基于实际应用案例——金融信贷业务场景的运行结果。对于消费金融机构来说,拒绝推断是一个长期存在的课题,风控、获客、盈利能力之间的关系难以平衡;风控越严格,不良率越低,获客成本越高,反之风控越弱,不良率越高,获客成本越低,坏账率越高。通过试用DarwinML 2.0的Beta版本中的拒绝推断功能,探智立方的企业用户在实际测试中指出,DarwinML 2.0中自动拒绝推断功能重新更正其未放贷用户的标签后,在风险降低1个百分点的同时,单月放款用户比例提高了11%。极大提升了企业自身的盈利能力。
受这次疫情的影响,消费金融业务也面临着这一突发情况所带来的逾期率剧增的冲击,多家消费金融公司也及时响应,提出了推迟还款期、减免逾期利息等政策。而如何正确区分出恶意逾期和复工延迟导致的逾期,并对后者能够做到合理的缓交免息支持,手工建立这样一个模型往往需要数周,并且需要业务人员和建模团队的深度配合。针对这一问题,探智立方的团队对消费金融企业用户提供全力支持,基于Darwin 2.0平台,仅依托于企业用户现有数据在一周之内完成了模型的设计、训练和应用,在体现消费金融机构践行社会责任的同时,也有效减缓消费金融机构不良率的上升。
DarwinML产品总监宋煜表示:“从1.0到2.0的版本升级,DarwinML最大的演进就是从‘易于构建’发展到‘易于构建,易于扩展,和易于应用’,从解决企业用户业务增长的角度出发提升易用性,赋能给企业的普通开发人员,使其能够深度的结合公司业务并快速做出他们想要的模型。”据悉,探智立方已在官网开启新版本的试用申请,企业及开发者可直接在探智立方官网申请试用。
探智立方是全球领先的AI技术和解决方案提供者,基于自主研发的DarwinML平台为AI在各行业的应⽤赋能,为企业客户提供一站式、全自动的模型⽣成和部署能力。作为企业AI赋能平台,DarwinML以先进的演化算法及强大技术作为支撑,从根本上协助企业将人工智能⾼效构建到业务应用和决策中,在降低AI门槛的同时,加速实现企业的智能化升级和转型。未来,探智立方还将加大研发力度,基于核心算法引擎持续优化提升模型设计的效率和模型的性能,进一步提升DarwinML的易用性与企业实际需求的结合度,普惠各行各业。
来源:业界供稿
好文章,需要你的鼓励


OpenAI与微软签署初步协议修订合作条款
OpenAI和微软宣布签署一项非约束性谅解备忘录,修订双方合作关系。随着两家公司在AI市场竞争客户并寻求新的基础设施合作伙伴,其关系日趋复杂。该协议涉及OpenAI从非营利组织向营利实体的重组计划,需要微软这一最大投资者的批准。双方表示将积极制定最终合同条款,共同致力于为所有人提供最佳AI工具。

让AI推理像人一样思考,但又要快得多:中山大学团队的“智能剪刀“如何给O1模型瘦身
中山大学团队针对OpenAI O1等长思考推理模型存在的"长度不和谐"问题,提出了O1-Pruner优化方法。该方法通过长度-和谐奖励机制和强化学习训练,成功将模型推理长度缩短30-40%,同时保持甚至提升准确率,显著降低了推理时间和计算成本,为高效AI推理提供了新的解决方案。

国产R1人形机器人亮相,挑战特斯拉Optimus霸主地位
中国科技企业发布了名为R1的人形机器人,直接对标特斯拉的Optimus机器人产品。这款新型机器人代表了中国在人工智能和机器人技术领域的最新突破,展现出与国际巨头竞争的实力。R1机器人的推出标志着全球人形机器人市场竞争进一步加剧。

视觉语言模型在自动驾驶中的可靠性大考验:上海AI实验室深度揭秘AI司机的真实水平
上海AI实验室研究团队深入调查了12种先进视觉语言模型在自动驾驶场景中的真实表现,发现这些AI系统经常在缺乏真实视觉理解的情况下生成看似合理的驾驶解释。通过DriveBench测试平台的全面评估,研究揭示了现有评估方法的重大缺陷,并为开发更可靠的AI驾驶系统提供了重要指导。

